NVIDIA Issac : https://www.nvidia.com/en-us/deep-learn ... /robotics/
http://hkm.appledaily.com/detail.php?gu ... e=20171014
... 在以往日子,開發人員在訓練演算法教授機械某種技能的時候,必須在真實環境下讓機器練習收集數據。在進行深度學習的時候,讓機械人經歷成千上萬次的測試練習是家常便飯。然而,NVIDIA發明的「Issac」,它融合VR和AI兩項技術,在虛擬世界透過VR搭建各類模仿現實的場景,設定各種測試情境,讓AI在此深度「修煉」,這個空間更排除現實世界的時間定律,AI能在一秒內反覆練習,還可以「組隊」,讓多個機械人同時訓練,只需數分鐘,就能完成耗時、花費高昂的實景測試,最後,將學習成果傳送到其他AI身上,完成訓練,投入實戰,大大加速學習效率。
「Issac」簡直就是AI的「神速學習器」,像漫畫《龍珠》中的「精神時光屋」,機械人進入「時光屋」後,在裡面完全不受外在世界的時間限制,達到訓練無極限的境界。相比真實世界,人類社會起碼要經歷千年才能累積的知識和技能,AI在「Issac」可能只需花費人界一天時間,就能全數學會,甚至遠遠超越!更厲害的是,「Issac」可把學習成果,直接大量「傳授」給其他機械人,讀者們還記得電影「廿二世紀殺人網絡」,男主角NEO學習功夫的情節嗎?只需將程式「Download」到腦裡面,一分鐘就能學會「蓋世神功」,成為絕頂武林高手。
日後,機械人只要在「Issac」極速學懂某項技能,「出關」後把成果「Upload」至雲端, 繼而再「Share」給所有正在服役的AI軍團,豈不是比武俠小說的「即時千里傳功大法」還厲害得多,想想!只需出入「精神時光屋」,再透過「Upload」和「Download」,就能瞬間將畢生功力升Level,不是神功又是什麼?

誰在線上
正在瀏覽這個版面的使用者: Google [Bot] 和 16 位訪客
咁撚勁?
5 篇文章 • 第 1 頁 (共 1 頁)








Re: 咁撚勁?
![]() 發表人 mtr 發表於 2017-10-19, 15:52
發表人 mtr 發表於 2017-10-19, 15:52

https://deepmind.com/blog/alphago-zero- ... g-scratch/
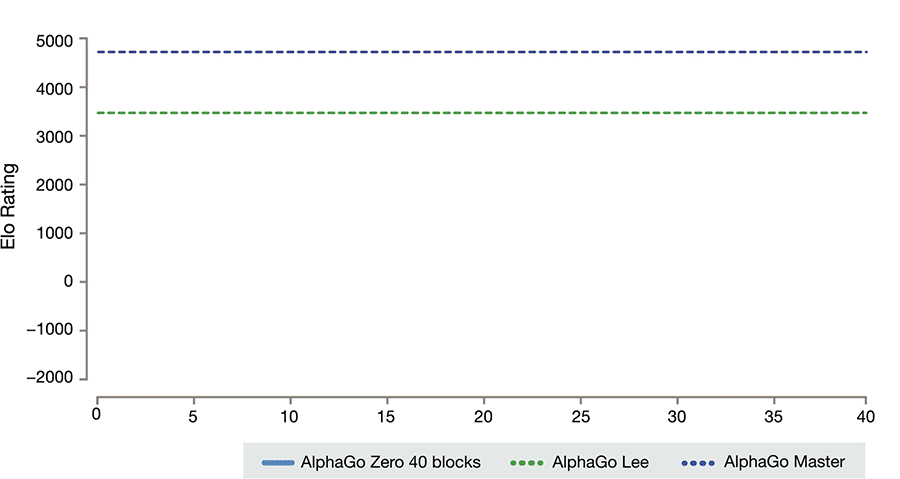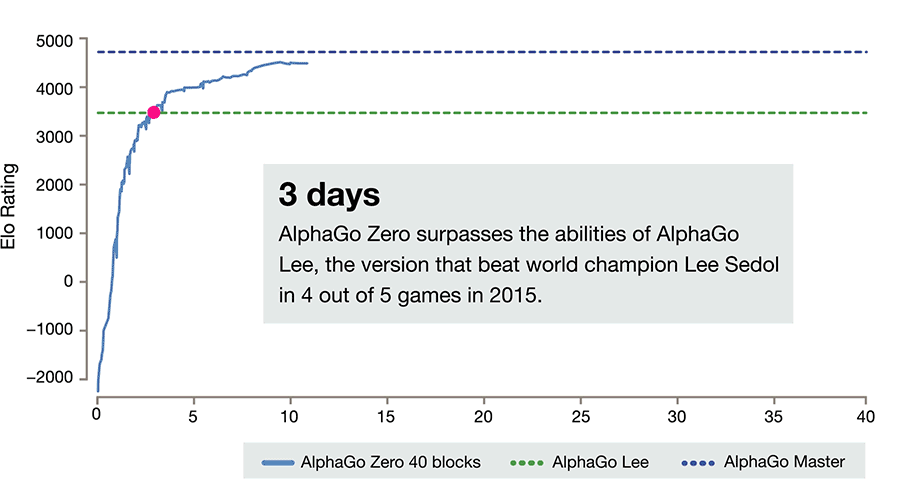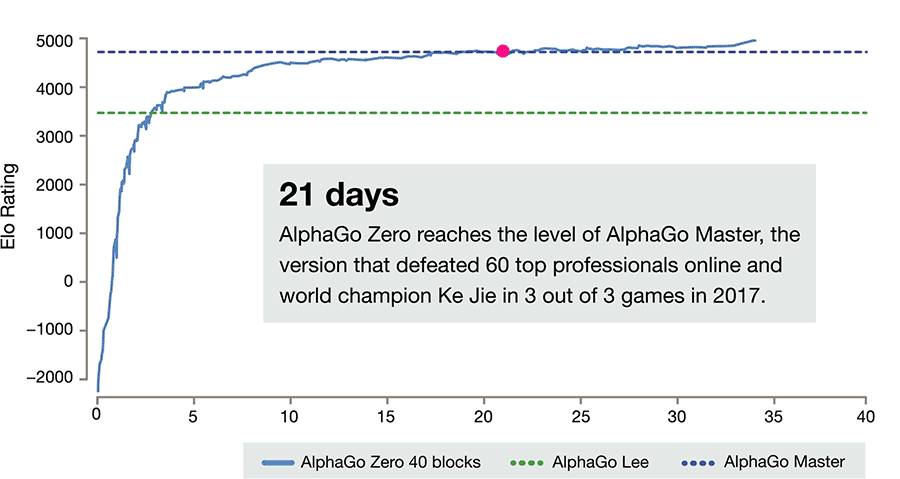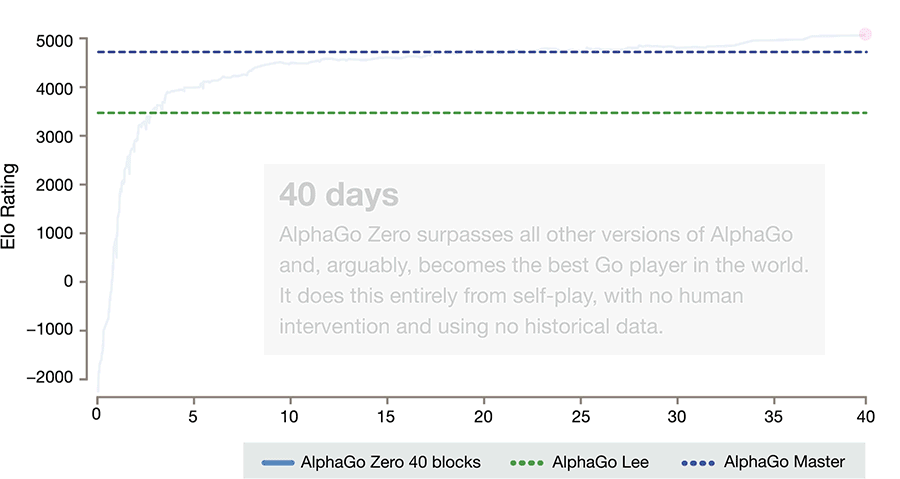
It also differs from previous versions in other notable ways.
- AlphaGo Zero only uses the black and white stones from the Go board as its input, whereas previous versions of AlphaGo included a small number of hand-engineered features.
- It uses one neural network rather than two. Earlier versions of AlphaGo used a “policy network” to select the next move to play and a ”value network” to predict the winner of the game from each position. These are combined in AlphaGo Zero, allowing it to be trained and evaluated more efficiently.
- AlphaGo Zero does not use “rollouts” - fast, random games used by other Go programs to predict which player will win from the current board position. Instead, it relies on its high quality neural networks to evaluate positions.

- 附加檔案
-
- 1.jpg (85.21 KiB) 被瀏覽 3672 次
-
mtr
- Fun區守護神 - 變淫大金剛

- 文章: 53293
註冊時間:
2007-04-17, 19:21

5 篇文章 • 第 1 頁 (共 1 頁)